


- 09/08/2022
In our last post on the topic of ‘Data Standards in Health Informatics - Part I’ we provided an overview of data standards in health informatics, and we covered SNOMED CT data standard in detail. In this post we will provide an in-depth view on ‘International Classification of Diseases (ICD) .
The International Classification of Diseases (ICD) is the oldest data standard, dating directly back to the 1800s and more indirectly to earlier centuries when researchers became interested in the causes of human mortality. Traditionally, ICD is a list or classification of medical diagnoses maintained by the World Health Organization (WHO) since 1948 and updated every 10 years. The current version, ICD-10, was adopted in 1994 but was not adopted in the US until 2015. [ICD-11 was rolled out starting Jan 2022 ].
If you look at ICD data then whether it’s ICD-9 or ICD-10, depends on the date of service. If the date of service was before Oct 1, 2014, then ICD-9 was used to code the diagnosis. And for date of service on or after Oct 1, 2014, ICD-10 was used . The switch from ICD-9 to ICD-10 adds complexity in analyzing longitudinal data that spans both ICD-9 and ICD-10.
The switch from ICD-9 to ICD-10 was a substantial effort because ICD-10 is a major quantitative and qualitative expansion over ICD-9. While ICD-9 had 13,000 codes the ICD-10 has some 68,000 codes to represent very specific clinical details.
One of the major differences between ICD-9 and 10 is presence of 'laterality' in ICD-10, something ICD-9 did not have. In technical terms, laterality is localization of function or activity on one side of the body in preference to the other, e.g., "Malignant neoplasm of right female breast, left-outer quadrant". There is almost 50% expansion of the number of codes in ICD-10 (over ICD-9) because of laterality.
The table below shows how one ICD-9 code can map to three potential ICD-10 codes due to presence of laterality in ICD-10:

Beyond size, ICD-10 is an ontology capable of representing clinical relationships not represented in ICD-9. For example, ICD-10 can encode the fact that a patient has gout affecting their right ankle and foot and they have developed a uric acid deposit, called a tophus, in that area. ICD-9 cannot specifically code for gout located in the ankle and foot, much less on the right side.
The figure below shows the various components of the ICD-10 code:
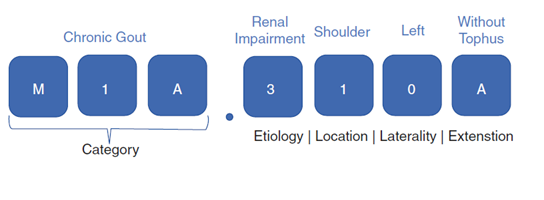
Here is one more example to understand ICD-10 code better:
S52       Fracture of forearm
S52.5     Fracture of lower end of radius
S52.52   Torus fracture of lower end of radius
S52.521 Torus fracture of lower end of right radius
S52.521A Torus fracture of lower end of right radius, initial encounter for closed fracture
In the above example, S52 is the category. The fourth and fifth characters of “5” and “2” provide additional clinical detail and anatomic site. The sixth character "1" in this example indicates laterality, i.e., right radius. The seventh character, “A”, is an extension that provides additional information, which means “initial encounter” in this example. It also demonstrates the use of the full code titles, which was not the format in the ICD-9 diagnosis code set.
The ICD-10 code sets include greater detail, changes in terminology, and expanded concepts for injuries, laterality, and other related factors. The complexity of ICD-10 provides many benefits because of the increased level of detail conveyed in the codes. The complexity also underscores the need to be adequately trained on ICD-10 in order to fully understand reporting changes that have come with the new code sets.
Sources:
[1] This article has been inspired by Mark L. Braunstein's book: "Health Informatics on FHIR: How HL7's API is Transforming Healthcare (Second Edition)"
